According to the 2015 Tufts Center for the Study of Drug Development, it now costs $2.6B to get a new drug to market. This figure represents the average cost of total research and development dollars spent divided by the total number of drugs approved. Overtime there has been a gradual decrease in drug development efficiency, as it requires increasingly more capital to successfully bring a drug to market.
There are four primary drivers of this increase in cost and decrease in efficiency and output of the drug development process.
1. Increases in generics raise the bar for new medicine, as companies are prioritizing tougher medical challenges with lower probability of success.
2. The public and regulatory body are concerned by the safety of new technologies such as CAR-T and CRISPR, which could require additional evidence from larger studies.
3. We are trying to take advantage of the newly discovered science to make novel drugs, while still lacking the understanding of its complex biology.
4. Industry consolidation limits creative diversity.
Breaking down the $2.6B cost, about 42% is spent on preclinical discovery and animal studies while the remaining 57% is spent on human trials. There are various ways machine learning is helping to reduce those costs in both pre-clinical and clinical settings.
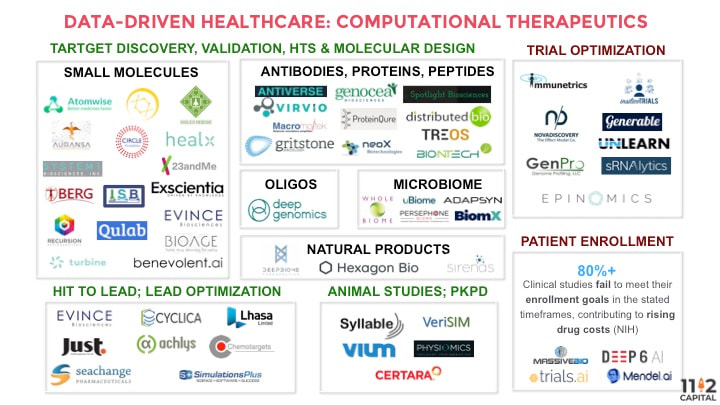
For example, in pre-clinical, discovery settings, pharmaceutical companies screen millions of small molecule compounds against targets, looking for some physical interaction. For example, startups such as Atomwise are applying machine learning to model and predict molecular docking. The company has trained a convolutional neural network using molecule structures and binding information to predict whether existing drugs will bind to a new target. Insilico Medicine uses adversarial autoencoder to generate novel structures that will inhibit cancer cell growth. Recursion Pharmaceuticals images tens of thousands of cells to extract structural features. Using these cellular “fingerprints” of healthy and disease cells, the company can ask whether any drug rescues diseased cells back to health. In oligonucleotide-based therapy discovery, our portfolio company Deep Genomics uses deep learning to more accurately predict which antisense oligonucleotides (ASO) are going to work on which target.
Similarly, when screening compounds for toxicity in pre-animal testing, current pharmaceutical process standards would physically screen the drug molecule against <100 proteins/compounds that are known to cause side effects. Machine learning startups such as Cyclica and BenevolentAI are disrupting this field. Cyclica has created a database of proteins to predict toxicity through docking and surface matching. BenevolentAI employs PrOCTOR, which uses random forest and a set of molecular properties, target-based properties, and drug-likeness rule features to predict toxicity.
Importantly, the growing numbers of industry partnerships validate such applications of machine learning approaches to drug discovery and bioscience research. AstraZeneca has partnered with Berg Health, which uses deep learning on clinical data and molecular data generated through mass spec of diseased vs. healthy tissues. It then ranks the genes, proteins or metabolites it finds according to their relevance to a particular disease, and determines when specific genes or proteins are associated with certain patient outcomes. Such screening is “at least 50% cheaper” than traditional methods, says CEO Dr. Niven Narain. Sanofi and GSK have partnered with UK-based Exscientia, which has developed a platform to design and evaluate novel compounds for predicted criteria, including potency, selectivity, and ADME, against specific targets. In addition, BenevolentAI has partnered with LifeArc, and Atomwise struck a partnership with Merck.
In clinical, human-trial settings, the NIH reported that greater than 80% of clinical studies fail to meet their enrollment goals in the stated timeframes, contributing to rising drug costs. We are seeing a slew of machine learning startups looking to better match patients to clinical trials. Deep6 Analytics applies deep learning to clinical data in the electronic health records to find patients that match trial protocol. Mendel.ai uses NLP to comb through ClinicalTrials.gov to provide a list of personalized trial matches to a particular patient. Trials.ai uses deep learning to help biotech/pharma companies optimize trial design.
As an early stage venture capital investor in the intersection of computer science and bioscience, we are excited about the breakthrough innovations in this space. We are seeing more and more companies - startups and established players alike - incorporating machine learning into their R&D process in order to capitalize on the increasing availability of molecular and clinical data as well as advancements in computational techniques to reduce the costs and cycle times associated with drug development. Particularly, machine learning innovation has decreased drug discovery costs and increased efficiency through computational prediction of efficacy and safety. Nevertheless, in order for this interdisciplinary field to succeed, we will need access to larger amounts of data and better understanding of our biology.
There are four primary drivers of this increase in cost and decrease in efficiency and output of the drug development process.
1. Increases in generics raise the bar for new medicine, as companies are prioritizing tougher medical challenges with lower probability of success.
2. The public and regulatory body are concerned by the safety of new technologies such as CAR-T and CRISPR, which could require additional evidence from larger studies.
3. We are trying to take advantage of the newly discovered science to make novel drugs, while still lacking the understanding of its complex biology.
4. Industry consolidation limits creative diversity.
Breaking down the $2.6B cost, about 42% is spent on preclinical discovery and animal studies while the remaining 57% is spent on human trials. There are various ways machine learning is helping to reduce those costs in both pre-clinical and clinical settings.
For example, in pre-clinical, discovery settings, pharmaceutical companies screen millions of small molecule compounds against targets, looking for some physical interaction. For example, startups such as Atomwise are applying machine learning to model and predict molecular docking. The company has trained a convolutional neural network using molecule structures and binding information to predict whether existing drugs will bind to a new target. Insilico Medicine uses adversarial autoencoder to generate novel structures that will inhibit cancer cell growth. Recursion Pharmaceuticals images tens of thousands of cells to extract structural features. Using these cellular “fingerprints” of healthy and disease cells, the company can ask whether any drug rescues diseased cells back to health. In oligonucleotide-based therapy discovery, our portfolio company Deep Genomics uses deep learning to more accurately predict which antisense oligonucleotides (ASO) are going to work on which target.
Similarly, when screening compounds for toxicity in pre-animal testing, current pharmaceutical process standards would physically screen the drug molecule against <100 proteins/compounds that are known to cause side effects. Machine learning startups such as Cyclica and BenevolentAI are disrupting this field. Cyclica has created a database of proteins to predict toxicity through docking and surface matching. BenevolentAI employs PrOCTOR, which uses random forest and a set of molecular properties, target-based properties, and drug-likeness rule features to predict toxicity.
Importantly, the growing numbers of industry partnerships validate such applications of machine learning approaches to drug discovery and bioscience research. AstraZeneca has partnered with Berg Health, which uses deep learning on clinical data and molecular data generated through mass spec of diseased vs. healthy tissues. It then ranks the genes, proteins or metabolites it finds according to their relevance to a particular disease, and determines when specific genes or proteins are associated with certain patient outcomes. Such screening is “at least 50% cheaper” than traditional methods, says CEO Dr. Niven Narain. Sanofi and GSK have partnered with UK-based Exscientia, which has developed a platform to design and evaluate novel compounds for predicted criteria, including potency, selectivity, and ADME, against specific targets. In addition, BenevolentAI has partnered with LifeArc, and Atomwise struck a partnership with Merck.
In clinical, human-trial settings, the NIH reported that greater than 80% of clinical studies fail to meet their enrollment goals in the stated timeframes, contributing to rising drug costs. We are seeing a slew of machine learning startups looking to better match patients to clinical trials. Deep6 Analytics applies deep learning to clinical data in the electronic health records to find patients that match trial protocol. Mendel.ai uses NLP to comb through ClinicalTrials.gov to provide a list of personalized trial matches to a particular patient. Trials.ai uses deep learning to help biotech/pharma companies optimize trial design.
As an early stage venture capital investor in the intersection of computer science and bioscience, we are excited about the breakthrough innovations in this space. We are seeing more and more companies - startups and established players alike - incorporating machine learning into their R&D process in order to capitalize on the increasing availability of molecular and clinical data as well as advancements in computational techniques to reduce the costs and cycle times associated with drug development. Particularly, machine learning innovation has decreased drug discovery costs and increased efficiency through computational prediction of efficacy and safety. Nevertheless, in order for this interdisciplinary field to succeed, we will need access to larger amounts of data and better understanding of our biology.